Python实战基础16 |
您所在的位置:网站首页 › sleep 10是什么意思 › Python实战基础16 |
Python实战基础16
|
Python中的模块
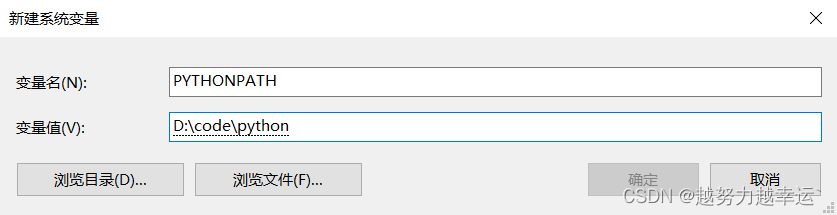
Python提供了强大的模块支持,主要体现为不仅在python标注库中包含了大量的模块(称为标准模块),而且还有很多第三方模块,另外开发者自己也可以开发自定义模块。 说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块。 例如:我们使用random,就是一个模块。使用import random导入工具之后,就可以使用random的函数。 在Python中,一个扩展名为“.py”的文件就称之为一个模块。 通常情况下,把能够实现某一特定功能的代码放置在一个文件中作为一个模块,从而方便其他程序和脚本导入并使用。另外,使用模块也可以避免函数名和变量名冲突。 且随着程序不断变大,为了便于维护,需要将其分为多个文件,这样可以提高代码的可维护性。使用模块还可以提高代码的可重用性。 1.1 常见系统模块常见的内置模块有: os模块sys模块math模块random模块datetime模块time模块calendar模块hashlib模块hmac模块copy模块uuid模块 1.1.1 os模块OS全称OperationSystem,即操作系统模块,这个模块可以用来操作系统的功能,并且实现跨平台操作。 import os os.getcwd() # 获取当前的工作目录,即当前python脚本工作的目录 os.chdir('test') # 改变当前脚本工作目录,相当于shell下的cd命令 os.rename('毕业论文.txt','毕业论文-最终版.txt') # 文件重命名 os.remove('毕业论文.txt') # 删除文件 os.rmdir('demo') # 删除空文件夹 os.removedirs('demo') # 删除空文件夹 os.mkdir('demo') # 创建一个文件夹 os.chdir('C:\\') # 切换工作目录 os.listdir('C:\\') # 列出指定目录里的所有文件和文件夹 os.name # nt->widonws posix->Linux/Unix或者MacOS os.environ # 获取到环境配置 os.environ.get('PATH') # 获取指定的环境配置 os.path.abspath(path) # 获取Path规范会的绝对路径 os.path.exists(path) # 如果Path存在,则返回True os.path.isdir(path) # 如果path是一个存在的目录,返回True。否则返回False os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False os.path.splitext(path) # 用来将指定路径进行分隔,可以获取到文件的后缀名 1.1.2 sys模块该模块提供对解释器使用或维护的一些变量的访问,以及与解释器强烈交互的函数。 import sys sys.path # 模块的查找路径 sys.argv # 传递给Python脚本的命令行参数列表 sys.exit(code) # 让程序以指定的退出码结束 sys.stdin # 标准输入。可以通过它来获取用户的输入 sys.stdout # 标准输出。可以通过修改它来百变默认输出 sys.stderr # 错误输出。可以通过修改它来改变错误删除 1.1.3 math模块math模块保存了数学计算相关的方法,可以很方便的实现数学运算。 import math print(math.fabs(-100)) # 取绝对值 print(math.ceil(34.01)) #向上取整 print(math.factorial(5)) # 计算阶乘 print(math.floor(34.98)) # 向下取整 print(math.pi) # π的值,约等于 3.141592653589793 print(math.pow(2, 10)) # 2的10次方 print(math.sin(math.pi / 6)) # 正弦值 print(math.cos(math.pi / 3)) # 余弦值 print(math.tan(math.pi / 2)) # 正切值 1.1.4 random模块random 模块主要用于生成随机数或者从一个列表里随机获取数据。 print(random.random()) # 生成 [0,1)的随机浮点数 print(random.uniform(20, 30)) # 生成[20,30]的随机浮点数 print(random.randint(10, 30)) # 生成[10,30]的随机整数 print(random.randrange(20, 30)) # 生成[20,30)的随机整数 print(random.choice('abcdefg')) # 从列表里随机取出一个元素 print(random.sample('abcdefghij', 3)) # 从列表里随机取出指定个数的元素 1.1.5 datetime模块datetime模块主要用来显示日期时间,这里主要涉及 date类,用来显示日期;time类,用来显示时间;dateteime类,用来显示日期时间;timedelta类用来计算时间。 import datetime print(datetime.date(2020, 1, 1)) # 创建一个日期 print(datetime.time(18, 23, 45)) # 创建一个时间 print(datetime.datetime.now()) # 获取当前的日期时间 print(datetime.datetime.now() + datetime.timedelta(3)) # 计算三天以后的日期时间 1.1.6 time模块除了使用datetime模块里的time类以外,Python还单独提供了另一个time模块,用来操作时间。time模块不仅可以用来显示时间,还可以控制程序,让程序暂停(使用sleep函数) print(time.time()) # 获取从1970-01-01 00:00:00 UTC 到现在时间的秒数 print(time.strftime("%Y-%m-%d %H:%M:%S")) # 按照指定格式输出时间 print(time.asctime()) #Mon Apr 15 20:03:23 2019 print(time.ctime()) # Mon Apr 15 20:03:23 2019 print('hello') print(time.sleep(10)) # 让线程暂停10秒钟 print('world') 1.1.7 calendar模块calendar模块用来显示一个日历,使用的不多,了解即可。 calendar.setfirstweekday(calendar.SUNDAY) # 设置每周起始日期码。周一到周日分别对应 0 ~ 6 calendar.firstweekday()# 返回当前每周起始日期的设置。默认情况下,首次载入calendar模块时返回0,即星期一。 c = calendar.calendar(2019) # 生成2019年的日历,并且以周日为其实日期码 print(c) #打印2019年日历 print(calendar.isleap(2000)) # True.闰年返回True,否则返回False count = calendar.leapdays(1996,2010) # 获取1996年到2010年一共有多少个闰年 print(calendar.month(2019, 3)) # 打印2019年3月的日历 1.1.8 hashlib模块hashlib是一个提供字符加密功能的模块,包含MD5和SHA的加密算法,具体支持md5,sha1, sha224, sha256, sha384, sha512等算法。 该模块在用户登录认证方面应用广泛,对文本加密也很常见。 import hashlib # 待加密信息 str = '这是一个测试' # 创建md5对象 hl = hashlib.md5('hello'.encode(encoding='utf8')) print('MD5加密后为 :' + hl.hexdigest()) h1 = hashlib.sha1('123456'.encode()) print(h1.hexdigest()) h2 = hashlib.sha224('123456'.encode()) print(h2.hexdigest()) h3 = hashlib.sha256('123456'.encode()) print(h3.hexdigest()) h4 = hashlib.sha384('123456'.encode()) print(h4.hexdigest()) 1.1.9 hmac模块HMAC算法也是一种一种单项加密算法,并且它是基于上面各种哈希算法/散列算法的,只是它可以在运算过程中使用一个密钥来增增强安全性。hmac模块实现了HAMC算法,提供了相应的函数和方法,且与hashlib提供的api基本一致。 h = hmac.new('h'.encode(),'你好'.encode()) result = h.hexdigest() print(result) # 获取加密后的结果 1.1.10 copy模块copy模块里有copy和deepcopy两个函数,分别用来对数据进行深复制和浅复制。 import copy nums = [1, 5, 3, 8, [100, 200, 300, 400], 6, 7] nums1 = copy.copy(nums) # 对nums列表进行浅复制 nums2 = copy.deepcopy(nums) # 对nums列表进行深复制 1.1.11 uuid模块UUID是128位的全局唯一标识符,通常由32字节的字母串表示,它可以保证时间和空间的唯一性,也称为GUID。通过MAC地址、时间戳、命名空间、随机数、伪随机数来保证生产的ID的唯一性。随机生成字符串,可以当成token使用,当成用户账号使用,当成订单号使用。 方法作用uuid.uuid1()基于MAC地址,时间戳,随机数来生成唯一的uuid,可以保证全球范围内的唯一性。uuid.uuid2()算法与uuid1相同,不同的是把时间戳的前4位置换为POSIX的UID。不过需要注意的是python中没有基于DCE的算法,所以python的uuid模块中没有uuid2这个方法。uuid.uuid3(namespace,name)通过计算一个命名空间和名字的md5散列值来给出一个uuid,所以可以保证命名空间中的不同名字具有不同的uuid,但是相同的名字就是相同的uuid了。namespace并不是一个自己手动指定的字符串或其他量,而是在uuid模块中本身给出的一些值。比如uuid.NAMESPACE_DNS,uuid.NAMESPACE_OID,uuid.NAMESPACE_OID这些值。这些值本身也是UUID对象,根据一定的规则计算得出。uuid.uuid4()通过伪随机数得到uuid,是有一定概率重复的uuid.uuid5(namespace,name)和uuid3基本相同,只不过采用的散列算法是sha1一般而言,在对uuid的需求不是很复杂的时候,uuid1或者uuid4方法就已经够用了,使用方法如下: import uuid print(uuid.uuid1()) # 根据时间戳和机器码生成uuid,可以保证全球唯一 print(uuid.uuid4()) # 随机生成uuid,可能会有重复 # 使用命名空间和字符串生成uuid. # 注意一下两点: # 1. 命名空间不是随意输入的字符串,它也是一个uuid类型的数据 # 2. 相同的命名空间和想到的字符串,生成的uuid是一样的 print(uuid.uuid3(uuid.NAMESPACE_DNS, 'hello')) print(uuid.uuid5(uuid.NAMESPACE_OID, 'hello')) 1.2 导入模块 1.2.1 导入模块有五种方式 import 模块名from 模块名 import 功能名from 模块名 import *import 模块名 as 别名from 模块名 import 功能名 as 别名 1.2.2 import在python中用关键字import来引入某个模块,比如要引入系统模块math,就可以在文件最开始的地方用import math来引入 语法: import 模块1,模块2,.... # 导入方式 模块名.函数名() # 使用模块里的函数 为什么必须得加上模块名调用呢? 因为可能存在在多个模块中含有相同名称的函数,此时如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。所以在引入模块的时候,调用函数必须加上模块名。 import math # 这样才能正确输出结果 print(math.sqrt(2)) # 这样会报错 print(sqrt(2))说明:在调用模块中的变量、函数或者类时,需要在变量名、函数名或者类名前添加”模块名作为前级。例如:上面代码中的math.sqrt,表示调用spirit模块中的sqrt()函数。 1.2.3 form... import当只需要用到模块中的某个函数,只需要引入该函数即可 from 模块名 import 函数名1,函数名2,... 模块名称,区分字母大小写,需要和定义模块时设置的模块名称大小写保持一致。 不仅可以引入函数,还可以引入一些全局变量、类等 多学两招: 在导入模块时,如果使用通配符导入全部定义后,想查看具体导入了哪些定义,可以通过显示dir()函数的值来查看。 import math print(dir(math))运行结果: ['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']注意:通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前面一次引入。也就是说假如模块A中有函数function(),在模块B中也有函数function(),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。 例如,要导入模块fib的fibonacci函数,使用如下语句: from fib import fibonacci 注意:不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个函数引入 1.2.4 from ... import *把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明: from modname import* 注意:这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。 1.2.5 as别名 import time as tt # 导入模块时设置别名为tt # print(time.sleep(1)) # 会报错 NameError: name 'time' is not defined print(tt.sleep(1)) # 使用别名才能调用方法 from time import sleep as sp # 导入方法时设置别名 #print(sleep(1)) # 会报错 NameError: name 'sleep' is not defined print(sp(1)) # 使用别名才能调用方法 1.2.6 练习【任务描述】 新建两个模块,在两个模块中有同名的函数出现,重新新建一个函数,如何正确地导入和使用这两个模块中地同名函数。 创建两个模块,一个是泸州老窖模块,其中包括返回3年52度和38度酒价格的函数;另一个是茅台模块,同样其中包括返回3年52度和38度酒价格的函数,作为区别,我们将52度酒的函数传进一个参数,然后在另一个python文件中导入这两个模块,并调用相应的函数计算52度和38度酒的价格。 创建矩形模块,对应的文件快,在该文件中定义两个函数,一个用于返回38度酒的价格,另一个用于返回52度酒的价格。 def thirty_eight(): # 返回泸州老窖3年38度酒的价格为200 return "泸州老窖3年38度酒的价格为200" def fifty_two(): # 返回泸州老窖3年52度酒的价格 return "州老窖3年52度酒的价格为300" if __name__ == '__main__': thirty_eight = thirty_eight() print(thirty_eight)创建茅台模块,在该文件中定义两个函数,一个用于返回38度酒的价格,另一个用于返回52度酒的价格。 def thirty_eight(): # 返回泸州老窖3年38度酒的价格 return "泸州老窖3年38度酒的价格为100" def fifty_two(degree): # 返回泸州老窖3年52度酒的价格 if degree == 3: return "泸州老窖3年52度酒的价格为150" if degree == 5: return "泸州老窖3年52度酒的价格为250" else: return ("请输入正确的酒藏年限,我们只有三年酒和五年酒") if __name__ == '__main__': price = fifty_two(4) print(price) 1.3 自定义模块自定义模块的作用: 规范代码,让代码更易于阅读方便其它程序使用已经编写好的代码,提高开发效率。实现自定义模块: 创建模块导入模块创建模块时,可以将模块中相关的代码(变量定义和函数定义等)编写在一个单独的文件中,并且将该文件命名为”模块名+.py“的形式 注意: 如果一个py文件要作为一个模块被别的代码使用,这个py文件的名字一定要遵守标识符的命名规则。创建模块时,设置的模块名不能是Python自带的标准模块名称。 1.4 模块搜索目录当使用import语句导入模块时,默认情况下,会按照以下顺序进行查找。 在当前目录(即执行的Python脚本文件所在目录)下查找到PYTHONPATH(环境变量)下的每个目录中查找到python的默认安装目录下查找以上各个目录的具体位置保存在标准模块sys的sys.path变量中。可以通过以下代码输出具体目录。 import sys print(sys.path) # 打印出模块路径运行结果: ['C:\\Users\\十二\\PycharmProjects\\test\\模块和包', 'C:\\Users\\十二\\PycharmProjects\\test', 'C:\\Program Files\\JetBrains\\PyCharm 2020.3.5\\plugins\\python\\helpers\\pycharm_display', 'C:\\Program Files\\Python37\\python37.zip', 'C:\\Program Files\\Python37\\DLLs', 'C:\\Program Files\\Python37\\lib', 'C:\\Program Files\\Python37', 'C:\\Program Files\\Python37\\lib\\site-packages', 'C:\\Program Files\\JetBrains\\PyCharm 2020.3.5\\plugins\\python\\helpers\\pycharm_matplotlib_backend']注意:使用import语句导入模块时,模块名是区分字母大小写的。 可以通过以下3种方式添加指定的目录到sys.path中 1.4.1 临时添加临时添加即在导入模块的Python文件中添加。例如,需要将”D:\code\python"目录添加到sys.path中,可以使用以下代码 import sys sys.path.append("D:\code\python")说明:通过该方法添加的目录只在执行当前文件的窗口中有效,窗口关闭后即失效。 1.4.2 增加.pth文件在python安装目录下的Lib\sitc-packages 子目录中(例如:Python安装在C:\Python\Python36目录下,那么该路径为C:\Python\Python36\Lib\site-packages),创建一个扩展名为.pth的文件,文件名任意。这里创建也给mrpath.pth文件,在该文件中添加要导入模块所在的目录。 例如:将模块目录“D:\code\python\"添加到mrpath.pth文件。 注意:创建.pth文件后,需要重新打开要执行的导入模块的Python文件,否则新添加的目录不起作用。 说明:通过该方法添加的目录只在当前版本的Python中有效。 1.4.3 在PYTHONPATH环境变量中添加打开”环境变量“对话框(,如果没有PYTHONPATH系统环境变量,则需要先创建一个,否则直接选中PYTHONPATH变量,在单击”编辑“按钮,并且在弹出对话框的”变量值“文本中添加新的模块目录,目录之前使用逗号进行分隔。 例如,创建系统环境变量PYTHONPATH,并指定模块所在目录为”D:/code/python;“,效果如下图:
注意:在环境变量中添加模块目录后,需要重新打开要执行的导入模块的Python文件,否则新添加的目录不起作用。 1.5 __all__的使用使用form import * 导入一个模块里所有的内容时,本质上是去查找这个模块的__all__属性,将__all__属性里声明的所有内容导入。如果这个模块里没有设置__all__属性,此时才会导入这个模块里的所有内容。 1.5.1 模块里的私有成员模块里以一个下划线_开始的变量和函数,是模块里的私有成员,当模块被导入时,以_开头的变量默认不会被导入。但是它不具有强制性,如果一个代码强行使用以_开头的变量,有时也可以。但是强烈不建议这样使用,因为有可能会出问题。 1.5.2 总结test1.py:模块里没有__all__属性 a = 'hello' def fn(): print('我是test1模块里的fn函数')test2.py:模块里有__all__属性 x = '你好' y = 'good' def foo(): print('我是test2模块里的foo函数') __all__ = ('x','foo')test3.py :模块里有以_开头的属性 m = '早上好' _n = '下午好' def _bar(): print('我是test3里的bar函数')demo.py from test1 import * from test2 import * from test3 import * print(a) fn() print(x) # print(y) 会报错,test2的__all__里没有变量 y foo() print(m) # print(_n) 会报错,导入test3时, _n 不会被导入 import test3 print(test3._n) # 也可以强行使用,但是强烈不建议 1.6 __name__的使用当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息。 例如:test1.py def add(a,b): return a+b # 这段代码应该只有直接运行这个文件进行测试时才要执行 # 如果别的代码导入本模块,这段代码不应该被执行 ret = add(12,22) print('测试的结果是',ret)demo.py import test1.py # 只要导入了tets1.py,就会立刻执行 test1.py 代码,打印测试内容为了解决这个问题,python在执行一个文件时有个变量__name__。在Python中,当直接运行一个py文件时,这个py文件里的__name__值是__main__,据此可以判断一个一个py文件是被直接执行还是以模块的形式被导入。 def add(a,b): return a+b if __name__ == '__main__': # 只有直接执行这个py文件时,__name__的值才是 __main__ # 以下代码只有直接运行这个文件才会执行,如果是文件被别的代码导入,下面的代码不会执行 ret = add(12,22) print('测试的结果是',ret)注意事项:在自定义模块时,需要注意一点,自定义模块名不要和系统的模块名重名,否则会出现问题。 |
【本文地址】
今日新闻 |
推荐新闻 |